Python is internally implemented as CPython, so looking into the compilation process of C makes it easier to understand its structure.
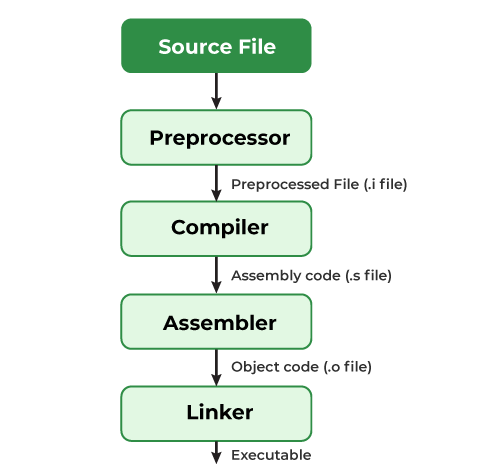
First, the compilation process of C is as follows:
-
The Preprocessor substitutes and inserts code based on the statements starting with #.
-
The Compiler receives this newly generated C file ending with .i.
-
The Compiler translates that file into Assembly language.
- Afterward, the Assembler translates the Assembly code into an Object file, and the Linker combines these Object files with libraries to generate the final executable file.
At this point, you might wonder, "Why not translate directly into machine code instead of translating it once more into human-readable Assembly language?" The answer naturally reveals itself when we look closer at the compiler's structure.
Let's examine the Compiler responsible for step 3. Concepts similar to web development appear here, so relating them will make it easier to understand. A Compiler is divided into a Frontend and a Backend.
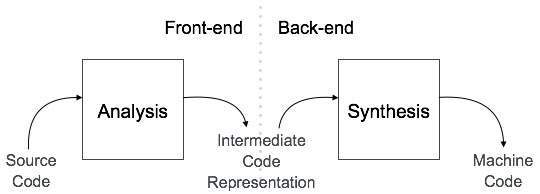
When the preprocessed file enters, the Frontend operations are executed first:
-
Lexical Analysis -> It breaks down the C script statements into units. For example, dividing them into [Keyword int], [Identifier a], [Operator +], etc. This is conceptually identical to React parsing HTML to construct the DOM.
-
Syntax Analysis -> Based on these units, it checks for grammatical correctness and builds an AST (Abstract Syntax Tree). Just like HTML, the scripts we write have operator precedence and scope, so they can form a tree structure similar to the DOM.
After generating the AST, the Compiler's Backend operations begin:
-
Intermediate Representation (IR) -> It traverses the AST to generate IR, an intermediate code independent of the target CPU. Here, it performs optimizations such as removing meaningless loops or unused variables.
-
Code Generation -> Based on the optimized IR, it translates the code into Assembly language suitable for the target CPU architecture and outputs it.
That is, the reason it goes through Assembly language instead of translating directly to machine code is partly for debugging the compiler's optimization results, but primarily because the machine code mapping for the target CPU is already handled by the Assembler. The optimization process is handled at the compiler level before the Assembly code turns into machine code, so it does not cause performance issues. Afterward, the Assembler simply maps the Assembly instructions to machine code.
So how does Python, known to have a specific interpreter, work? Let's figure it out by comparing it with the C compiler.
-
The process of performing the Compiler's Frontend operations to build an AST is identical to the C compiler.
-
Afterward, it goes through the Backend's IR phase. -> At this stage, optimization is performed in a significantly simplified manner compared to C. Specifically, it builds a CFG (Control Flow Graph) to eliminate Dead Code or pre-calculate constant expressions, and after this lightweight optimization, it formats the instructions into a 1D array.
-
It converts this into bytecode, Python's own Assembly language that only its Virtual Machine can understand.
-
It passes this bytecode instruction by instruction into the machine code switch-case loop contained within python.exe to execute them.
This 4th process is what is commonly referred to as the interpreter.
While we didn't cover python.exe in depth to focus on the compiler, in reality, when you enter the command to run a Python file in the terminal (python3 script.py), the OS loads python.exe into memory, and the CPU begins executing it. Subsequently, python.exe converts script.py into bytecode, and an Evaluation Loop runs inside the Virtual Machine to process the instructions.
Ultimately, the distinct characteristic of Python is how it sharply contrasts with C, where the CPU directly executes the finalized machine code file produced through the Assembler and Linker.